Running Open Weight Models On A Single Consumer Grade GPUs
How image generation and LLMs can boost productivity – and why running them locally matters

Why Open Models?
For years, the biggest language and vision systems were locked behind corporate APIs — from OpenAI, Antrhopic, Google etc.
Then DeepSeek came in — DeepSeek is one of the pioneers in open model space. a relatively unknown AI research lab from China, released an open source model that quickly become the talk back then. On many metrics that matter — capability, cost, openness ― DeepSeek is opening the way for open weight models in the industry.
Models like DeepSeek, Qwen, Llama , Stable Diffusion, Flux and many more coming have changed the game — giving us the ability to experiment, fine-tune, and run powerful models completely offline in our local.
Today, even consumer-grade GPUs from NVDIA or AMD is capable of running these models efficiently — powering real workflows and boost our productivity.
Even this article writing is refined by open weight model GPT OSS 20B and the featured image is generated by Flux Dev 1
How feasible it actually is? We’ll see through this article
What We Are Going To Have A Play With
| Category | Typical Use Cases | How It Boosts Productivity |
|---|---|---|
| Image Generation (Flux, Stable Diffusion) | Marketing creatives, Content Creation, Product design, editing and etc. | Generates high-quality assets in seconds, reducing design iteration time. |
| Large Language Models (LLMs) (DeepSeek, Qwen, GPT-OSS) | Agentic Coding, Content Writing, Text Summarization and etc. | Cuts developer hours, automates repetitive writing, and enables unlimited knowledge retrieval. |
💡 Both categories can now run comfortably on a single GPU wether it’s NVIDIA with its CUDA or AMD with its ROCm.
Open vs. Proprietary – The Realistic Trade-Offs
| Aspect | Open-Source Models | Closed / Proprietary Models |
|---|---|---|
| Cost | Zero inference cost (only electricity) | Pay-per-use, scales with usage |
| Data Privacy | 100 % local; no leaks | Cloud-hosted; vendor policies apply |
| Model Size | Smaller (7–30 B params) or quantized (4-bit) for consumer GPUs | Larger (>30 B), often need TPUs or 80 GB+ GPUs |
| Performance | Not as good as Proprietary but still feasible | Highest benchmark score, more performant |
| Latency | Low (runs locally) | Network delays & API queues |
In many workflows, a well-tuned open model on an consumer GPU can replace paid APIs — especially when privacy and cost control matter.
The Value of Running AI Locally
- Zero ongoing fees — inference is free after model download (we only pay for electricity tho)
- Full control over privacy — ideal for finance, healthcare, and sensitive data
- Customizable pipelines — integrate easily into workflow or automation
- Low latency — essential for IDE plugins, chatbots, or real-time tools
- Resilience — no dependence on external API uptime
💡 These playground below use consumer GPU with 24GB VRAM
Image Generation
Generating realistic image using Flux Dev 1
- Tools: ComfyUI
- Model: Flux Dev 1 FP8
- Model Size: 17.2GB
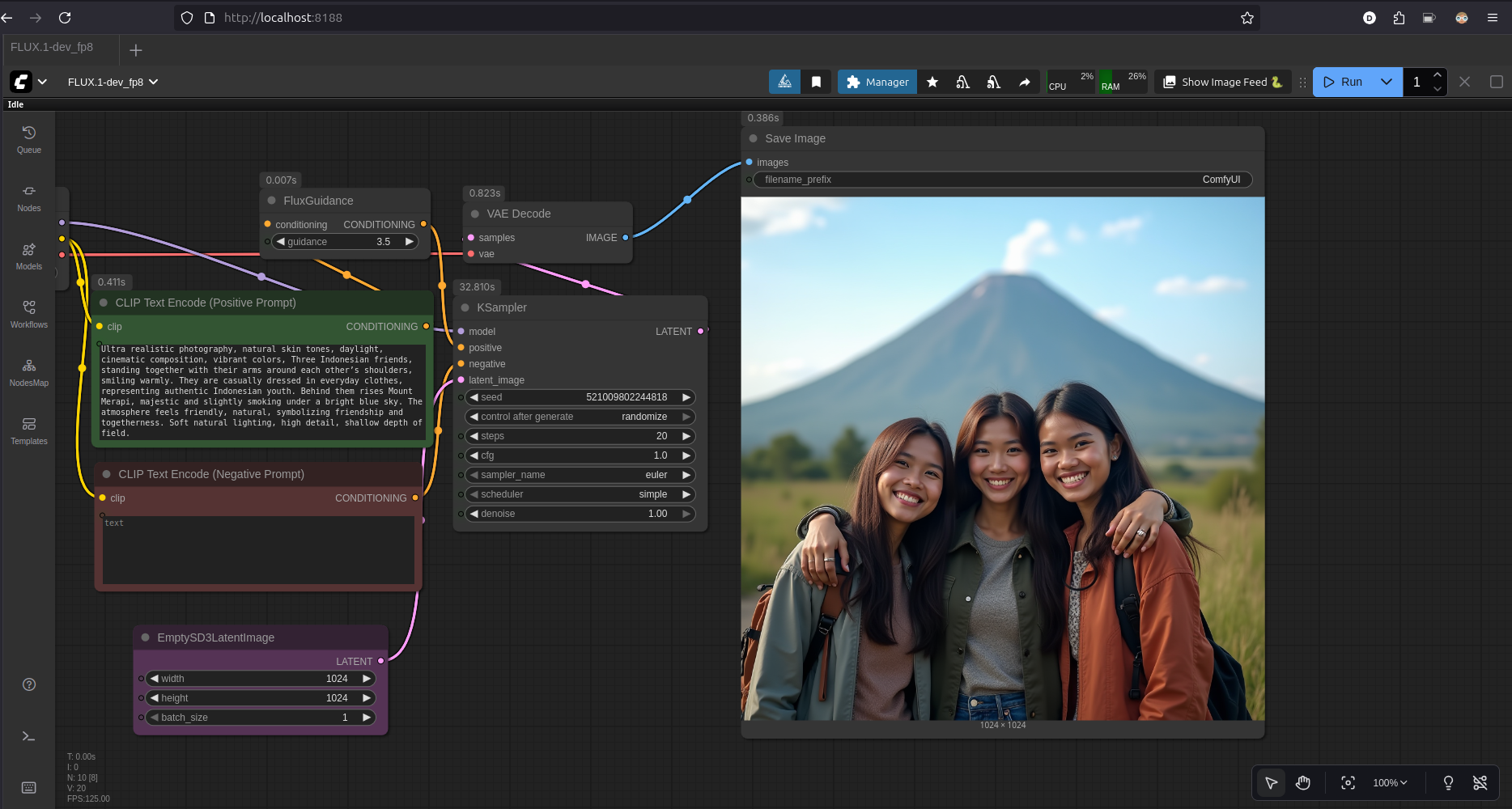
Image editing with Flux Kontext
- Tools: ComfyUI
- Model: Flux Dev 1 Kontext Q6
- Model Size: 9.8GB
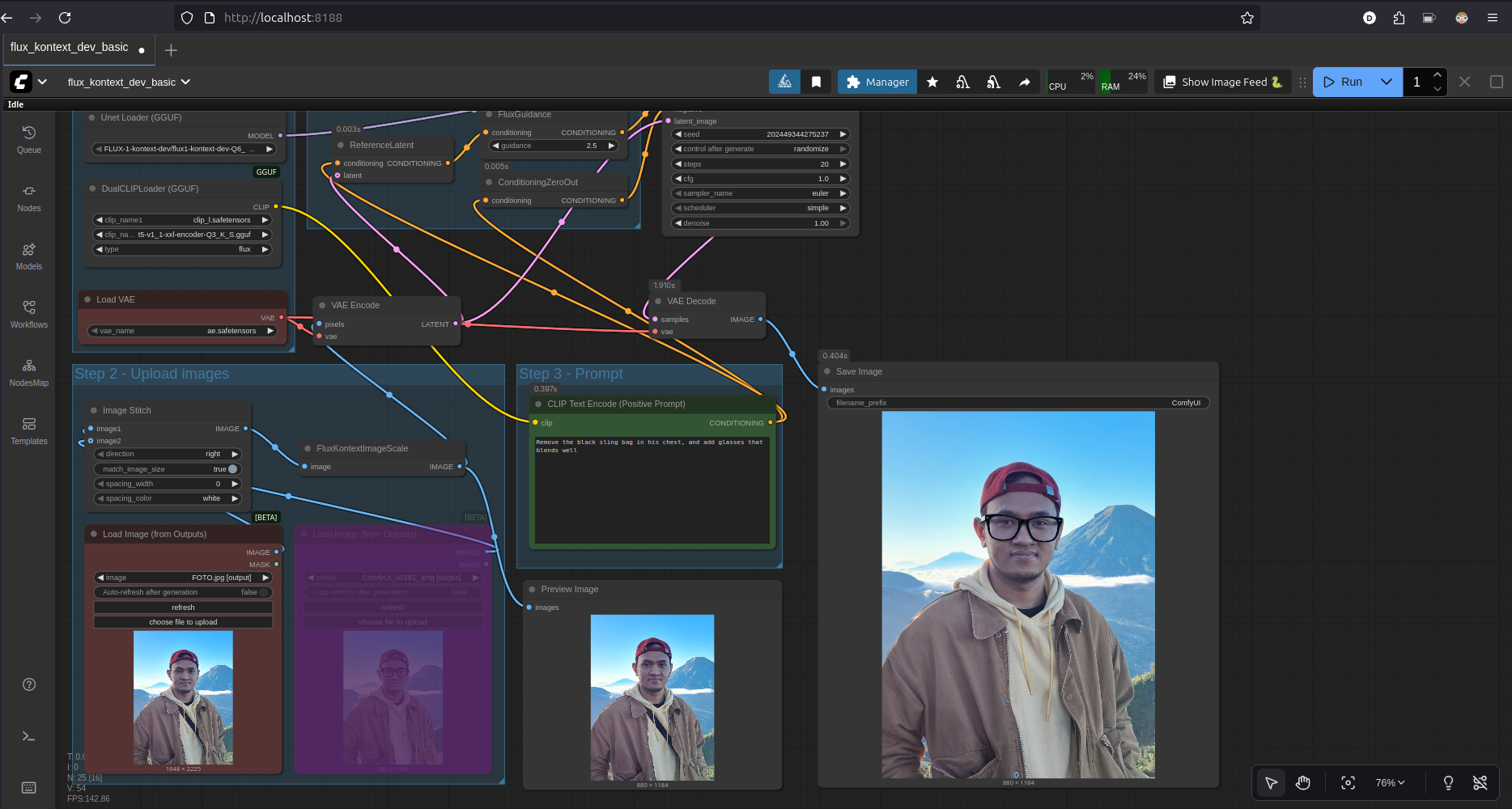
Another Flux Kontext example result:

Generating Brand Logo using Flux Dev 1 and LoRa
- Tools: ComfyUI
- Model: Flux Dev 1 FP8
- Model Size: 17.2GB
- LoRa Model: LoRa logo design
Another LoRa logo design example result:
LLM for Agentic coding
There are a lot of open-weight LLMs trained specifically for coding out there — like QWEN 3 Coder and DeepSeek Coder. they also have multiple model size variant, but of course smaller model version will not perform as good as model that run in a full precisions mode. To measure how capable a Large Language Model (LLM) is, the AI community uses standard benchmarks — shared evaluation tasks that allow fair comparison between models. These benchmarks test how well models understand, reason, and generate text across different domains.
One of the most significant modern benchmarks for LLMs — especially those aimed at software engineering — is SWE-Bench.
What it is:
SWE-Bench evaluates how well an LLM can understand, modify, and fix real-world codebases based on GitHub issues and pull requests. In other words, instead of toy coding problems, it uses actual bugs and features from popular open-source repositories.
Why it matters:
It tests end-to-end reasoning — from reading a bug report to editing multiple files, ensuring the code compiles, and passing unit tests. This makes it a practical measure of how close an LLM is to acting like a real software engineer.
Impact:
SWE-Bench has become the gold standard for assessing LLMs’ software engineering ability. Recent high-performing models like GPT-5, Claude Sonnet 4.5, and Gemini 2.5 Pro are often benchmarked using SWE-Bench to show real coding competence, not just text generation skills.
Let’s infer the best open weigh model available that we could run on single consumer grade GPU. Based on the SWE Bench verified, Devstral is scoring about 53%.
Here are the good articles showing the case
- https://openhands.dev/blog/devstral-a-new-state-of-the-art-open-model-for-coding-agents
- https://mistral.ai/news/devstral-2507
Now let’s give it a try..
Vibe Code
- Agent: Openhands
- Model: Devstral small 1.1 Q4
- Model Size: 14GB
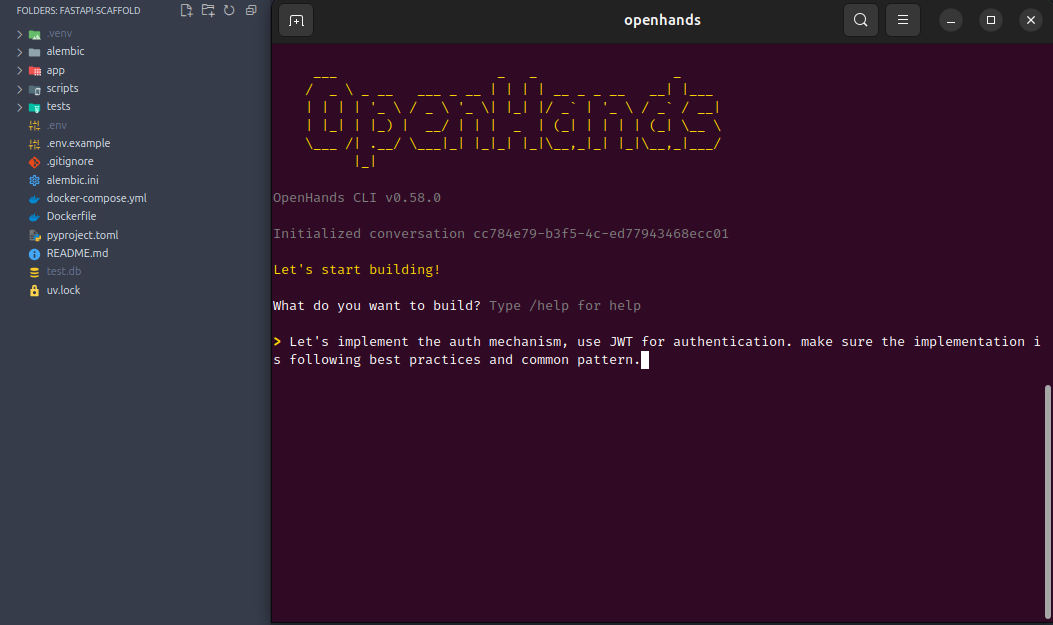
It will automatically write the code for you, just like when you’re using claude, cline, windsurf etc.
When vibe coding, make sure you’re being explicit in your prompt — also always double check the result and code quality of the generated code.
I think the security jargon is still make sense in the context of working with AI.
Never Trust, Always Verify
Bottom Line
Consumer GPUs have crossed the threshold — real AI workloads now run locally, efficiently, and securely.
Whether you’re a designer creating instant visuals or a developer building smarter tools, open models bring:
- 💰 Cost efficiency – no token or image fees
- 🔒 Privacy assurance – data stays on your device
- ⚡ Speed & control – instant inference, full tweakability
So far, proprietary models still hold the best overall performance compared to open models
But that doesn’t mean open models brings no value.
Open models are no longer academic toys — they’re practical, production-ready companions for everyday creativity and engineering.
So if you’ve been waiting to harness AI without breaking the bank or leaking data, now’s the time to plug in your GPU and start generating.